Welcome to the Berkeley Center for
Edge Computing
Sponsors


Overview
With generous funding from Intel and VMware, we have formed a new research center at Berkeley on Edge Computing. This effort is led by professors Sylvia Ratnasamy and Scott Shenker, and includes the entire NetSys group of roughly twelve graduate students and four postdocs and staff. Please see our people, project, and publication pages.
What is Edge Computing?
Edge Computing: Research Challenges
Edge computing raises many interesting issues that we are pursuing. Below is an evolving list of challenges that our research addresses.
Resiliency
Perhaps the biggest change from CDNs to today's edge computing is making the edge stateful, so application correctness can be undermined -- or its functioning stopped -- when an edge fails and its state disappears. We are addressing this in two ways. First, in our CESSNA project we provide a toolkit that can allow arbitrary client and server code to seamlessly recover from an edge failure (the edge code must be CESSNA-aware). Second, our Persimmon project uses in-memory applications (as most edge processing would be) to create persistent state without much additional overhead.
Privacy
With data passing through computational edges, edge computing must ensure privacy of data. Our TimeCrypt project allows scalable and real-time analytics to be run over large volumes of encrypted time series data.
Limited computation
Many of the “edges“ in edge computing are relatively small computing installations (rather than large datacenters). Thus, these edges must be prepared to cope with limited computing resources. Several of our projects (kappa, workstealing, CFM, prefetch, perf-predict, savanna, depsched), while not explicitly focused on the edge, provide techniques to use computing resources more efficiently
Self-managing
Similarly, many of the edge locations have no onsite operators, so they must be self-managing. Our AutoTune project automates the optimal placement of jobs to increase efficiency, and our AXE and Ark projects automate network resiliency.
Ad hoc distribution
For distributed applications like gaming, one never knows in advance which edges will have clients attached, yet the performance of the application depends on where state is placed. Our Edgy project allows operators to cope with this ad hoc distribution by enabling operators to seamlessly change where state is stored while maintaining the correctness of the application.
New paradigms
The preceding projects accept the basic computational and networking infrastructure as given, and provide ways to make it better. However, we also have projects that look to make fundamental changes in the underlying infrastructure. First, we are looking for how we might completely redesign operating systems to fit the modern age of computing. Second, we are investing radical new ways of designing cellular networks, where most edge computing clients will live. Lastly, we have proposed a restructuring of the Internet infrastructure that would greatly change how edges are deployed.
Overall View of Projects
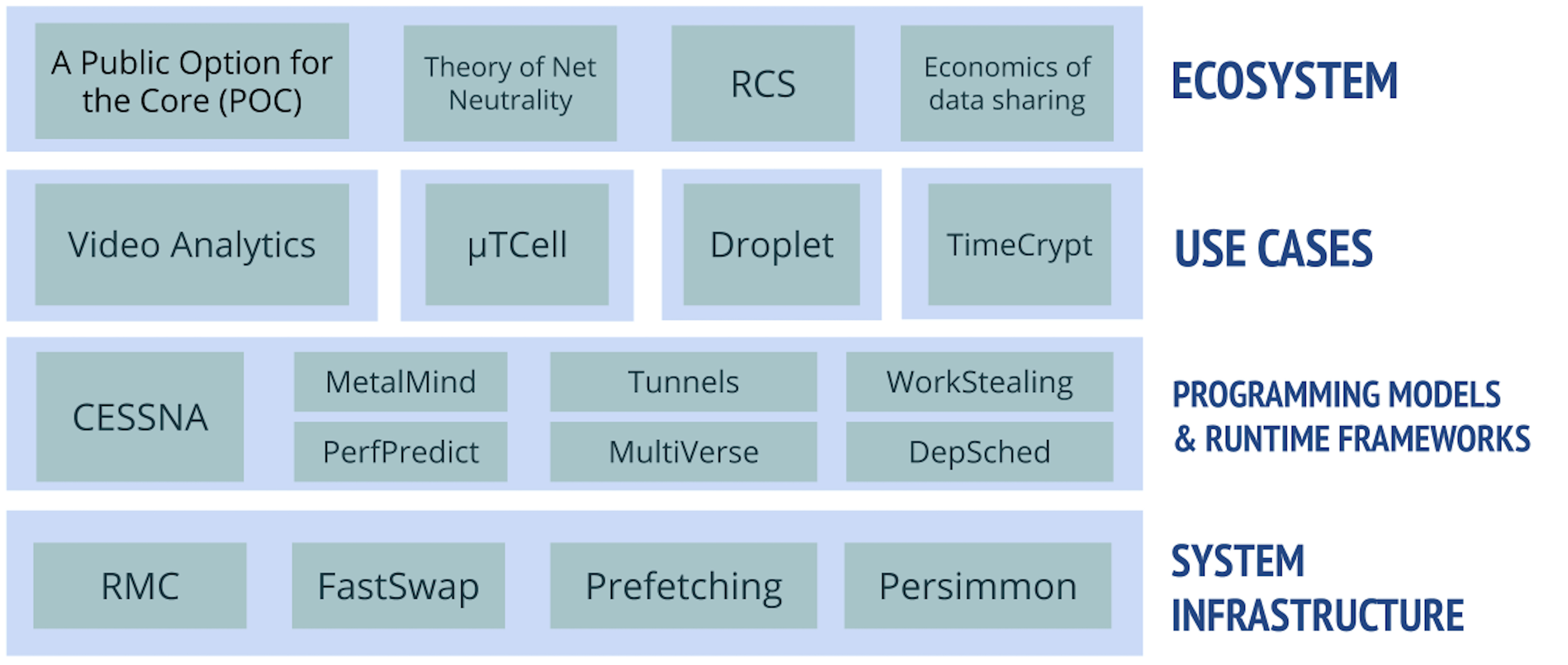
The above list of challenges have resulted in many projects. It is helpful to think of them falling into one of four categories:
Ecosystem These are projects that address how broader themes, like the overall Internet infrastructure or the nature of congestion control in the public Internet, that impact what happens at the edge.
Use Cases These are use cases that could utilize edge computing, ranging from new cellular designs to privacy and analytics.
Programming Models and Runtime Frameworks These projects involve software designs that would be run at the edge.
System Infrastructure These are advances in lower-level technology, such as extending RDMA or exploiting persistent memory, that edge solutions could use.